🔌 • chord-ish: implementing a simple membership protocol
 Chord-ish is a play implementation of the Chord protocol as described in this paper for use as the membership and failure detection layers for Chord-ish DeFiSh. In this post we’ll talk some about how it works, and why it is the way that it is.
Chord-ish is a play implementation of the Chord protocol as described in this paper for use as the membership and failure detection layers for Chord-ish DeFiSh. In this post we’ll talk some about how it works, and why it is the way that it is.
Membership & Failure Detection
In any distributed system there needs to be some way of knowing what other nodes (machines / processes) are members within a group. A membership layer achieves that by implementing some protocol that provides a consistent view of memberships within that group, thereby allowing nodes to discover and communicate with one another.
Also, as in any distributed system, failures are inevitable. Consequently, membership layers need to also be able to adapt to unexpected changes in membership. This requires a failure detection component, assigned with the task of detecting node failures or crashes.
Introducing, Chord-ish
To fill the role of the membership and failure detection layers for my highly convoluted and inefficient distributed key/value store, Chord-ish DeFiSh. I decided to implement bastardize Chord.
Why did I do this instead of building something way simpler, such as an all to all, all to one, or barebones gossip membership protocol? Because I saw Chord in a UIUC-CS425 lecture on peer-to-peer systems and thought it sounded really cool.
Many features were stripped out and many poor decisions were made, and my following description of the protocol will be specific to my usage of it and should not be trusted under any circumstances. I’ll use the name Chord-ish to identify my implementation.
Let’s begin!
Consistent Hashing, Finger Tables, & Membership Tables
First, some definitions and context.
Consistent hashing is the process by which a hash function is used to distribute K objects across N points on a virtual ring, where N = 2^m - 1. Here, m is an arbitrary constant that can be made larger or smaller, correlating directly with the expected number of nodes that the protocol will be supporting.
Why is this useful? Let’s say that we have a distributed key/value store that assigns server positions and key/value assignments as follows:
1assignedPoint := hash(IPAddr) % (Number of servers)
2assignedServer := hash(key) % (Number of servers)
Servers and key/value pairs are still evenly distributed here, yes, but if the number of servers is ever changed for something like a horizontal up or downscale, downtime is needed to rehash nodes and key/value pairs on to newly evaluated assignedPoints and assignedServers. Consistent hashing assigns inputs to points using a function that is independent of the total number of nodes within a group, meaning we can scale up or down without needing downtime to rehash.
Chord-ish works by using a consistent hashing function to assign the IP addresses (or any unique identifier) of an arbitrary number of nodes onto a virtual ring with 2^m - 1 points. Consistent hashing ideally distributes all nodes evenly across the ring, which leads to some built-in load-balancing which can be useful when using Chord-ish’s node’s as key/value stores, as we do in Chord-ish DeFiSh.
Chord-ish’s consistent hashing function is implemented in /internal/hashing.
1func MHash(address string, m int) int {
2 // Create a new SHA1 hasher
3 h := sha1.New()
4
5 // Write our address to the hasher
6 if _, err := h.Write([]byte(address)); err != nil {
7 log.Fatal(err)
8 }
9 b := h.Sum(nil)
10
11 // Truncate our hash down to m bits.
12 pid := binary.BigEndian.Uint64(b) >> (64 - m)
13
14 // Convert to an integer to get our ring "point", which
15 // doubles as our process/node ID.
16 return int(pid)
17}
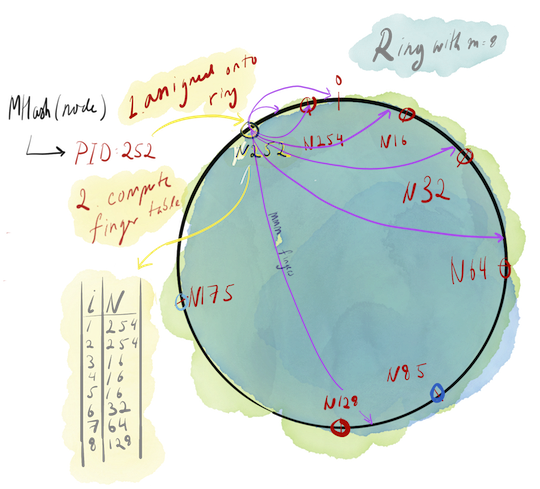
After a node is assigned onto the ring, it generates a finger table. Finger tables are Chord-ish’s routing tables, key/value maps of length m where the corresponding keys and values are as follows:
key = some integer i ranging from (0, m)value = (first node with PID >= (currentNode.PID + 2**(i - 1)) % (2**m))wherea**b= a^b.- The
… % (2 ** m)is important here. If some calculated value exceeds 2^m-1, then this modulo “wraps” the calculated value back around the ring. For an example, look at the visualization of the finger table calculations (the blue arrows) in the figure below.
- The
Finger tables are used in canonical Chord to enable O(log n) lookups from node to node, but because Chord-ish won’t actually be doing any storing of its own, finger tables here are only used to disseminate heartbeat and graceful termination messages. Doesn’t that defeat the purpose of going through all the trouble of implementing Chord? Haha! Yes. No one’s paying me to do this so I can do a bad job if I want. Not that I wouldn’t do a bad job if someone was paying me, either.
Another essential piece of state held by each node is a membership map. Membership maps are described as follows:
1// memberMap maps a node's PID to information about that node.
2var memberMap = make(map[int]*MemberNode)
3type MemberNode struct {
4 IP string
5 Timestamp int64 // The last time someone got a heartbeat from this node
6 Alive bool // Whether or not this node is suspected of having failed
7}
How nodes populate their membership maps will be discussed later.
Below is a diagram that demonstrates what’s been described so far. A node is born into this world, hashed onto a point onto the ring, and populates its finger table.
An Aside: The Introducer is Special
“But wait!", you exclaim, “how does the node know where the ring exists so it can join the group in the first place?” Simple! Chord-ish depends on an introducer node that the new or rejoining nodes can rely on to exist at a fixed IP address, from which they can request group information. This group information comes in the form of a populated membership map.
What happens if the machine running the introducer loses power, is disappeared by some powerful foreign government, or just gets busy with life and doesn’t respond to its messages anymore, as all things might do in distributed systems?
Communication & failure detection within the group, by Chord’s nature, proceeds as normally. However, new nodes or rejoining nodes are unable to connect to the group and will continuously ping the introducer node until they get a response.
Heartbeating
Now our node is all settled in and has populated its finger table. How does this node know that the other nodes are “alive”? The most common method of doing this is to have nodes continuously send messages, or heartbeats, at a fixed interval to one another. Any node that you don’t hear back from after a long enough time, can be assumed to have had some kind of failure.
Chord-ish’s heartbeating system works very similarly. Any functioning node will, at a fixed interval:
- Update the timestamp in its own entry in the membership map to be
time.Now().Unix() - Send heartbeats to all nodes in its finger table, as well as 2 of its immediate successors and its predecessor on the ring. For example, in the above figure, N252’s would heartbeat to the following nodes:
- N175, N254, N16, N32, N64, N128. Notice that we excluded N85 and N175. This is no issue though, as we can safely assume that these two excluded nodes will receive N252’s heartbeat information next round from the many nodes that received N252’s heartbeat information in the last round of heartbeats.
Nodes will continuously listen for heartbeats from other nodes, regardless of what they are doing.
These heartbeats can be used to identify failures and learn about membership changes. Below is a little visualization of the internals of a heartbeat and a brief description.
1, the internal integer constant indicating that this message is a heartbeatA membership map
node.PID, the PID of the sender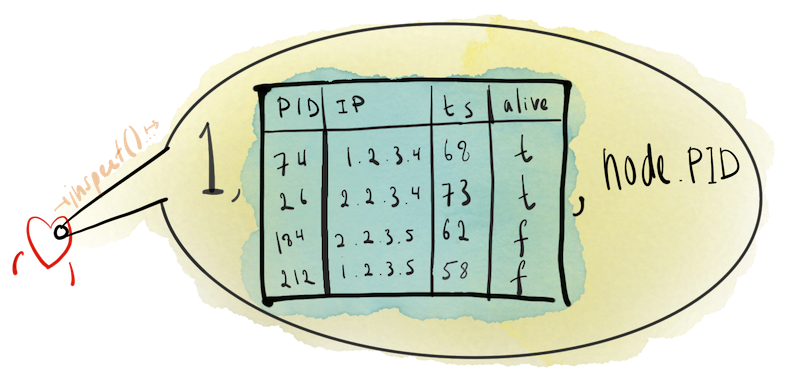
The actual heartbeat messages themselves, and all other communication in Chord-ish, is done via comma delimited strings encoded as bytes, as shown below.
1message := []byte(fmt.Sprintf(
2 "%d%s%s%s%d",
3 spec.HEARTBEAT, delimiter,
4 spec.EncodeMemberMap(&memberMap), delimiter,
5 selfPID,
6))
These messages are then sent to other nodes over UDP. On receiving a heartbeat, a node performs two actions.
- Merges its member map with that of the incoming membership map using the following code:
1// Loop through entries in the incoming member map
2for PID, node := range *theirs {
3// See if we also have this entry
4_, exists := (*ours)[PID]
5// If so, replace our entry with theirs if theirs is more recent
6if exists {
7 if (*theirs)[PID].Timestamp > (*ours)[PID].Timestamp {
8 (*ours)[PID] = node
9 }
10// If we don't have this entry, add it to our map.
11} else {
12 (*ours)[PID] = node
13}
- Updates its finger table.
Although nodes only heartbeat to nodes in their finger tables, two successors, and a single predecessor, all nodes within a group become up to date with membership information fairly quickly due to the gossipy nature of this heartbeating protocol. Some issues exist, however.
For example, in a poorly balanced ring “cold spots” can appear where some nodes can take so long to have their heartbeats propagated that other nodes begin to suspect that they have failed. The mechanism by which these suspicions are created is described in the next section.
Failure detection & Suspicion Mechanism
Chord-ish checks for failures immediately prior to dispatching heartbeats. This assures that information sent in a heartbeat is as accurate as can be allowed. Its failure detection mechanism, called CollectGarbage, requires another piece of state, the suspicion map. The suspicion map is defined below.
1// [PID:Unix timestamp at time of suspicion detection]
2var suspicionMap = make(map[int]int64)
3
4// The maximum difference between time.Now().Unix() and node.Timestamp
5// before a node is added to the suspicion map with value = node.Timestamp
6const timeFail = 6
7
8// The maximum difference between time.Now().Unix() and node.Timestamp
9// before a node is removed from the membership map
10const timeCleanup = 12
Nodes in the suspicion map are not treated any differently than non-suspected nodes, save for the fact that suspected nodes will have node.Alive == false in a sufficiently up-to-date node’s membership map, which will be shared with other nodes through heartbeats.
The suspicion map is used in conjunction with two integer constants, timeFail and timeCleanup. Whenever CollectGarbage is run, it executes according to the flowchart below, doing its first pass on the membership map and assigning things to either be ignored, added to the suspicion map, or outright deleted from the membership map and suspicion map.
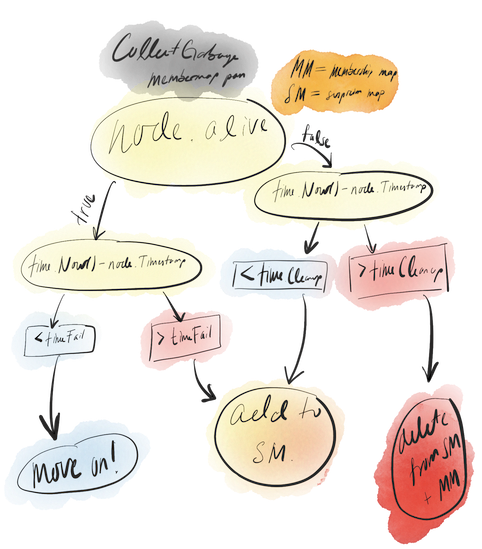
After it finishes its pass over the membership map, it does another pass over the suspicion map. Here, it simply checks whether or not to keep nodes under suspicion or to outright delete them.
You might ask: “Why even include this step of adding nodes to a suspicion map and differentiating from timeFailure and timeCleanup? Why force yourself to manage more state when failure detection would work fine without it?”
Imagine a scenario where CollectGarbage works by deleting a node F from the membership map the moment (time.Now() - node.Timestamp) > timeFailure. Immediately after this deletion, F recovers from a brief network outage and becomes active again. If the introducer is available, F should be able to rejoin the group without issues. However, there is some downtime between F coming back online and F rejoining the group.
Using Chord-ish’s suspicion mechanism, while F is down nodes are still actively trying to send it membership information. In this situation, as soon as F comes back online it begins receiving membership information and has minimal to no downtime before it can populate its finger table and begin heartbeating again.
Summary
Chord-ish is a membership layer that uses consistent hashing to assign nodes to a point on a virtual ring. Consistent hashing allows us to scale the number of nodes arbitrarily, without needing to rehash existing values.
Those nodes then communicate with one another by heartbeating to their successors and predecessors. Nodes can also identify other node failures by tracking the time between heartbeats. Information about node memberships and failures are piggybacked on heartbeats, allowing information to spread quickly through a group.
Chord-ish can tolerate random failures and membership changes with relative ease, given enough time between failures and that the core “introducer” node stays alive.
Chord-ish can be used as the membership layer underneath a different distributed system, as I did when building Chord-ish DeFish. If you’re curious about Chord-ish’s role in that system, you can read all about that in the links below.
Thanks for reading!